Velocity Propagation Protocol
Current Methods in Block Propagation:
Blockchain technology, although revolutionary in principle is not without it’s set of challenges in practice. At our current state, these blockchain networks have propagation methods that result in bottlenecks leading to high latency and more frequent orphaned blocks. High latency meaning long delays in network transmission, and orphaned blocks referring to blocks that have failed to propagate to the network. These challenges create long delays in transactions, high bandwidth requirments, and opens the door for malicious activity.
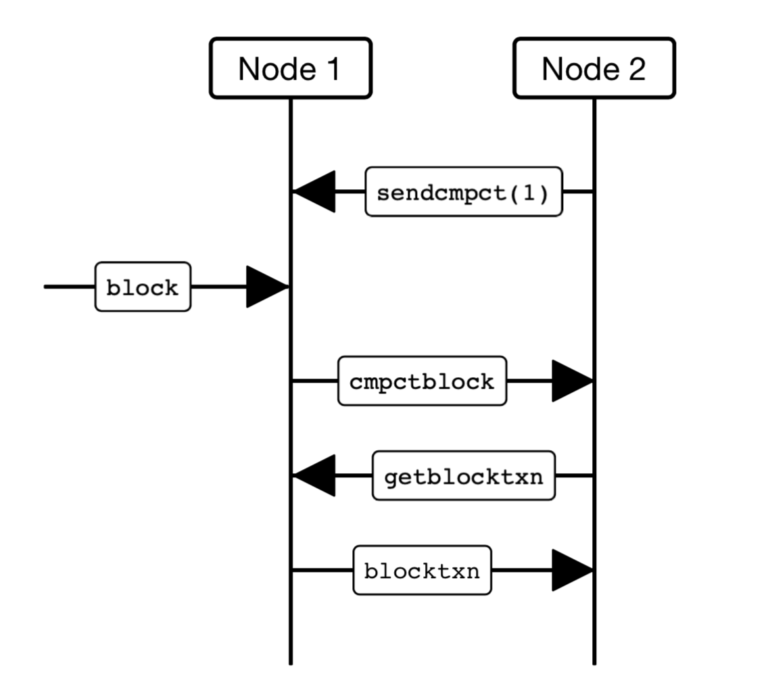
Researches in the propagation field have implemented strategies to improve block propagation methods in order to solve major setbacks in the technologies adoption. Most notably Bitcoin Improvement Protocol (BIP) 152 introduced compact blocks to accelerate the propagation process on the Bitcoin network. This approach provides a reduction in payload size of each block, decreasing the processing time for each node in the network. Unfortunately, this solution didn’t come without a caveat. In order to propagate these compact blocks, transmissions of “short IDs” are required between nodes to identify missing transactions. These ”short IDs” take up additional space creating bottlenecks, and high latency when a single node is required to process many unknown transactions. The figure to the right depicts a high bandwidth compact block propagation:
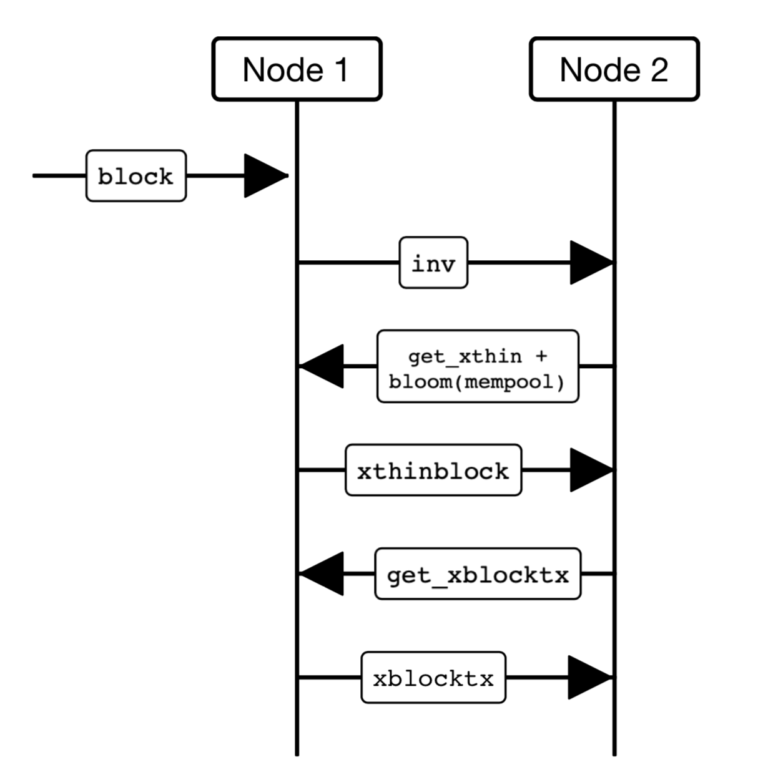
The next attempt to improve block propagation techniques was introduced in Bitcoin Unlimited Improvement Protocol (BUIP010) and was called Xtreme Thin Blocks (X-Thin Blocks). Leveraging bloom filters, this process has an advantage in being able to compare missing transactions more efficiently. However, X-thin blocks require back and forth communication between nodes which leads to delays in propagation for high latency networks. The added overhead of this process can also allow for malicious nodes to send falsified filters resulting in network collision attack. The figure to the right depicts an X-Thin Block Propagation:
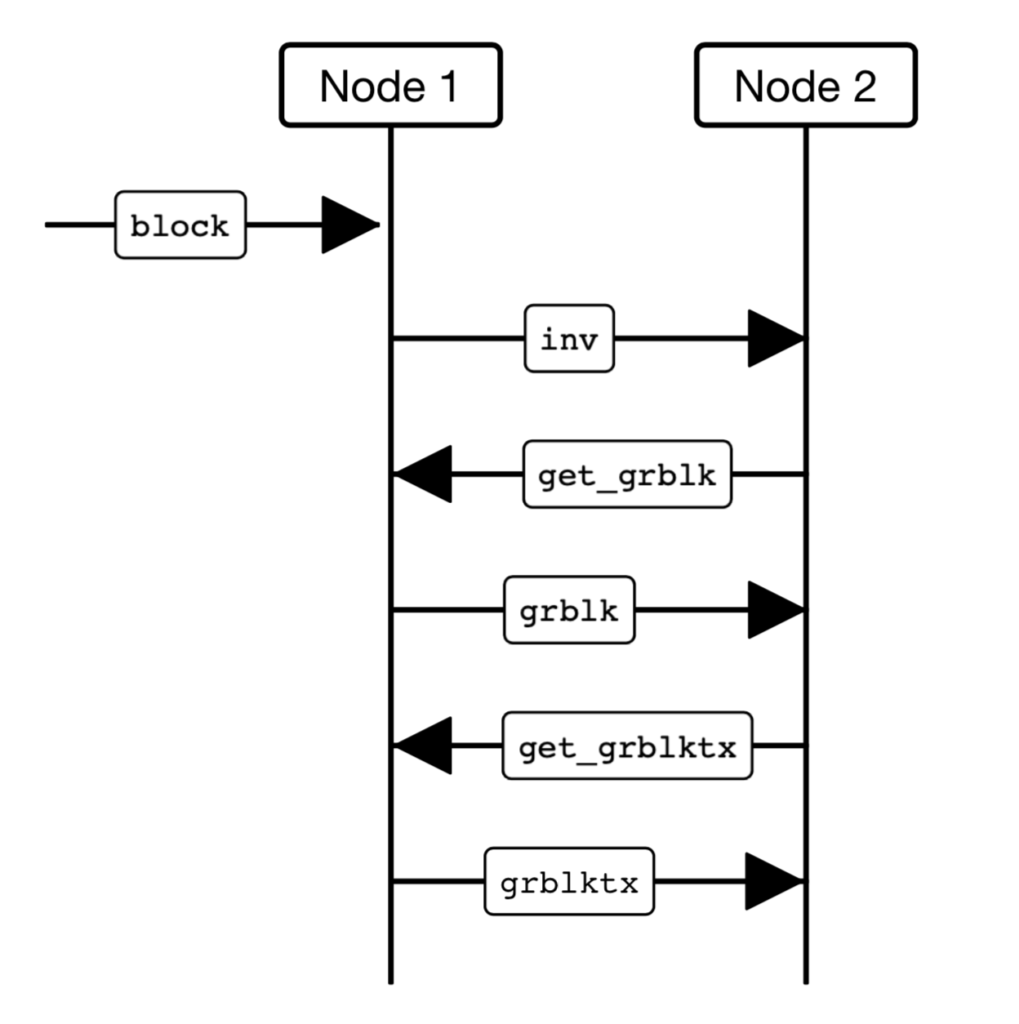
The last attempt of block propagation that we’re going to explore was implemented in Bitcoin Unlimited Improvement Protocol (BUIP093), called Graphene. To address the drawbacks of XThin blocks, Graphene used Invertible Bloom lookup tables (IBLT) to decrease the payload size of each block and improve propagation efficiency.
Implementation of Graphene has been successful due to its decrease in bandwidth utilization which offset the additional costs incurred by a more expensive computationally contributions. Unfortunately, like our other two proposed propagation methods, Graphene isn’t without its problems. This approach relies heavily on nodes maintaining an in-memory pool (or mempool) of transactions. This makes it impractical for synchronization between nodes as they are unaware of transactions. The figure to the right depicts block propagation using the Graphene method:
Each of the above propagation protocols relies on a single peer to send the complete block data as opposed to using multiple peers to transmit partial block data. That means that these methods can only be used to receive blocks that are currently being propagated, and cannot be used to sync new nodes. Researchers at the ASU Blockchain Research Lab have determined that existing methods of block propagation are inefficient. As a solution to the challenges blockchain networks faces with propagation, ASU researchers propose what they call Velocity block propagation.
Velocity Block Propagation Protocol:
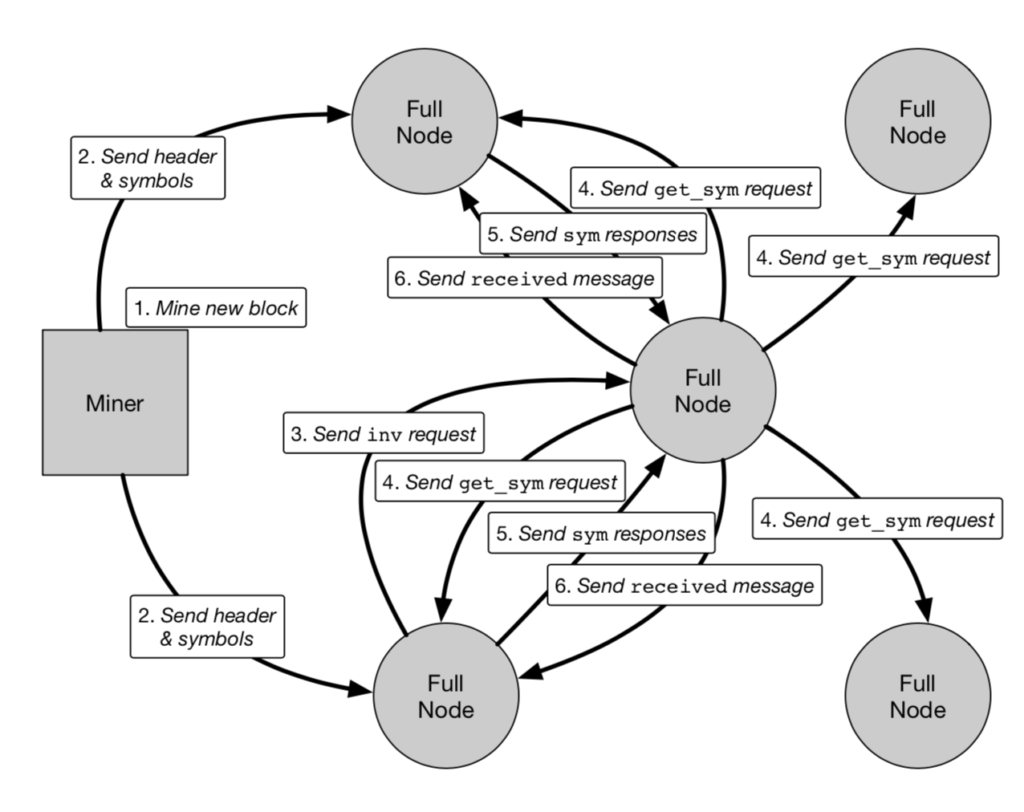
In order to address the challenges faced by traditional block propagation methods, researchers at Arizona State University have introduced a method called Velocity. This method uses the error recovery properties of rateless erasure codes to allow multi-origin, simultaneous-broadcast block propagation, rather than single-source direct transmission. This means that rather than having a single peer send the complete block data, they’re using a technique which allows for multiple peers to transmit partial block data. As detailed in section 3 of the research “Velocity: Breaking the Block Size Barrier” at a high-level the velocity protocol is as followed:
- A sender node, on hearing a new block, sends an inv to another peer. The whole block body is reinterpreted as a byte array and then encoded into a set of symbols of a length that was negotiated between the peers.
- On receiving the inv message, the receiver requests unknown blocks using an expedited get_sym request to all its peers.
- All peers who have heard of the block respond with sym, encoded symbols of the blocks. Other peers drop the message.
- The receiver collects these symbols in a singleton class, a map of block header ID to symbol ID and symbol pair. Note that symbols here can be significantly large. In order to prevent DoS attacks, every symbol must contain the un- encoded header. In smaller blocks, this can be optimized to send only the 64 byte hash along with every symbol.
- The receiver knows the amount of symbols needed to reconstruct the block, and waits until it receives the required count of the symbols.
- On reaching the required count, the receiver reconstructs the block.
Velocity Block Propagation Protocol sample flow:
Simulation Experiment:
Intentions of the experiment are to understand the scalability characteristics of Velocity with varying block sizes, symbol counts, and numbers of connections. The Velocity block propagation protocol ran on a Dash Network Simulator created by researcher Nakul Chawla. The network was initialized randomly in order to match the real-world distributions of the Dash Network. To model realistic transactions, researches use underlying information from which samples are taken uses real-world transaction data from the Dash blockchain. Transactions are randomly generated to maintain characteristics similar to real-world observations. Parameters of the research are as followed:
- S: Th block size in MB between 100MB to 1GB
- I: Block interval in seconds (I=150) taken from Dash network
- P: Propagation method Traditional or Velocity
- N: Number of blocks propagated N=100 equivalent to 15000 seconds
- K: Number of fountain code symbols per block varies between 10 to 10000
Research Performance Evaluation:
In order to evaluate the simulation’s performance, researchers track both block orphan rate (amount of mined blocks failed to be added to the blockchain), and the median block propagation time (median time cost (in seconds) for block propagation to all of the nodes). Researchers also observe the relationship between these outcomes and the predetermined block sizes and symbol sizes. Furthermore, they analyze the simulations data to determine the proper relationship between symbol size and block size for propagation to be optimal.
The observed data and interpretations for the simulated experiment as found in section 5 “Performance Evaluation” C2:
- For k = 10, we see that for 100MB blocks, the orphan rate starts at a low value of 9%, but it increases quickly with block size. This is because the symbol size becomes larger than the upload bandwidth for the node, and therefore takes additional time to propagate.
- For k = 100 and k = 1000, the orphan rate increases at almost the same rate. It is notable that the resulting symbols are relatively small, do not utilize the complete bandwidth of the node, and hence take less time to propagate, thereby reducing orphans.
- For k = 10000, in smaller block sizes (between 100MB and 400MB) the performance is optimal, although when the block sizes grow, the orphan rate becomes similar to that of k = 100 and k = 1000, although still significantly less than the orphan rates under the original block propagation method.
Orphaned Rates as found in section 5 “Performance Evaluation” C2:
- Under the original propagation scheme, the orphan rate approaches 97%; that is, almost all blocks produced are orphaned when using 1GB blocks. Additionally, for all block sizes between 100MB and 1GB, the network is unable to maintain consensus, establishing an upper- bound on (usable) block size under traditional schemes.
- In contrast, we see that when the data is aggregated from multiple peers, the orphan rate is contained below 50% for 400MB blocks with k = 10, and for k between 100 and 10000, the network maintains consensus below block sizes of 600MB.
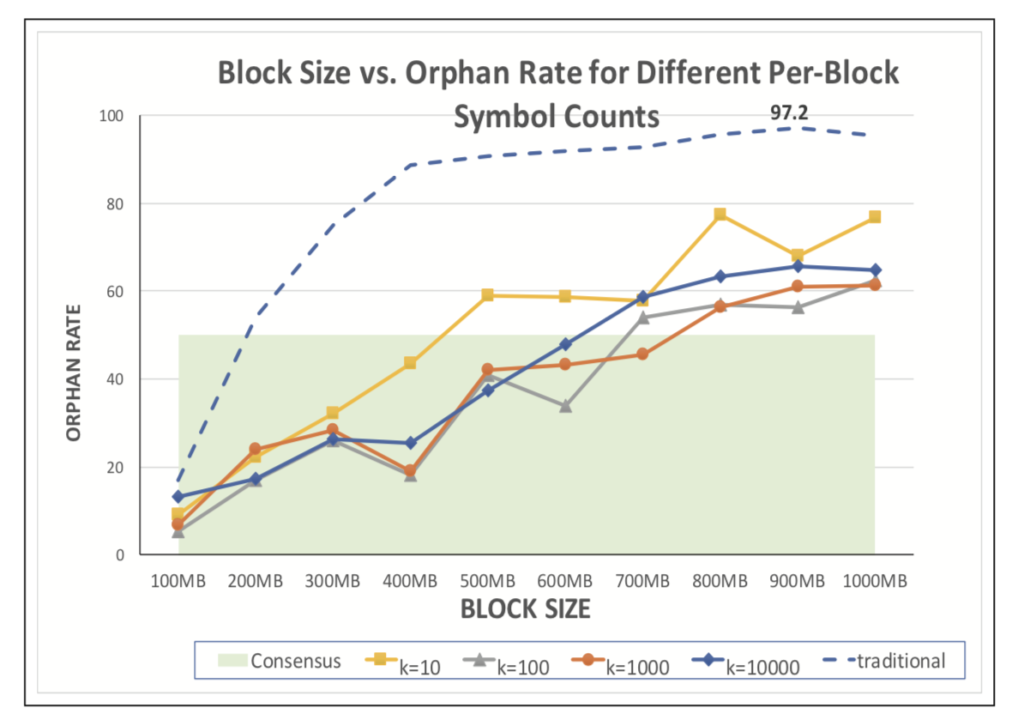
Block Propagation Times as found in section 5 “Performance Evaluation” C3:
- The median block propagation time cost for traditional approaches exceeds I with block sizes of 200MB. It is especially noticeable from the figure below that 200MB blocks are also not in consensus when using traditional propagation approaches.
- The median block propagation time cost remains below I using Velocity propagation for block sizes up to 400MB for k = 10, and up to 600MB for k between 100 and 10000. Furthermore, the figure below shows that consensus is maintained for block sizes up to 400MB for k = 10, and that consensus is maintained for block sizes of up to 600MB with k values between 100 and 10000.
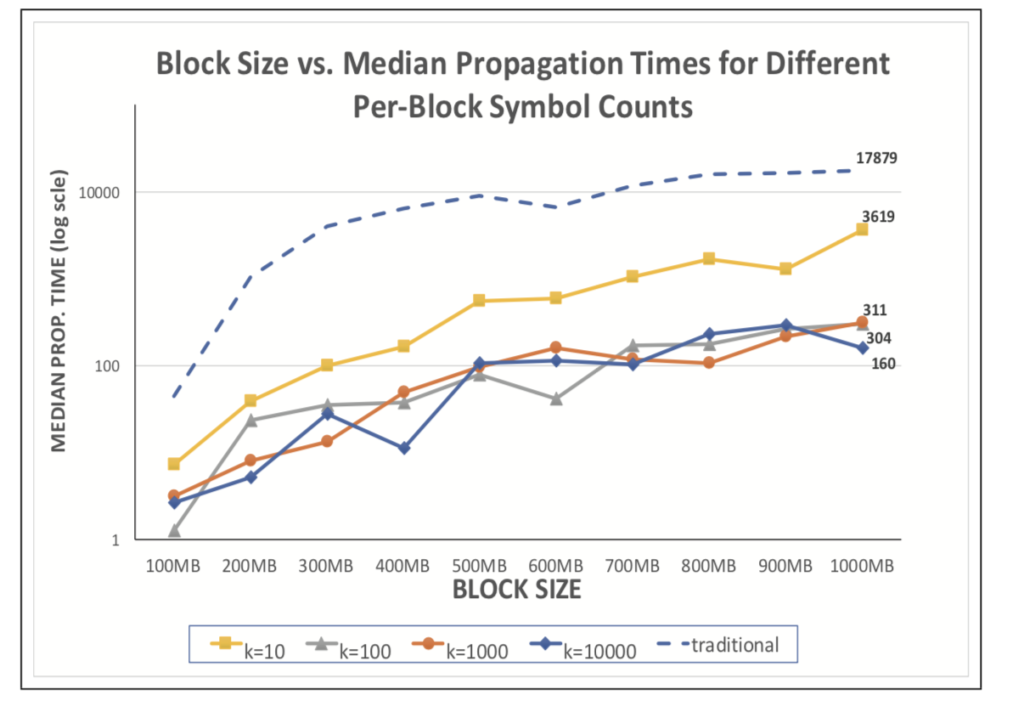
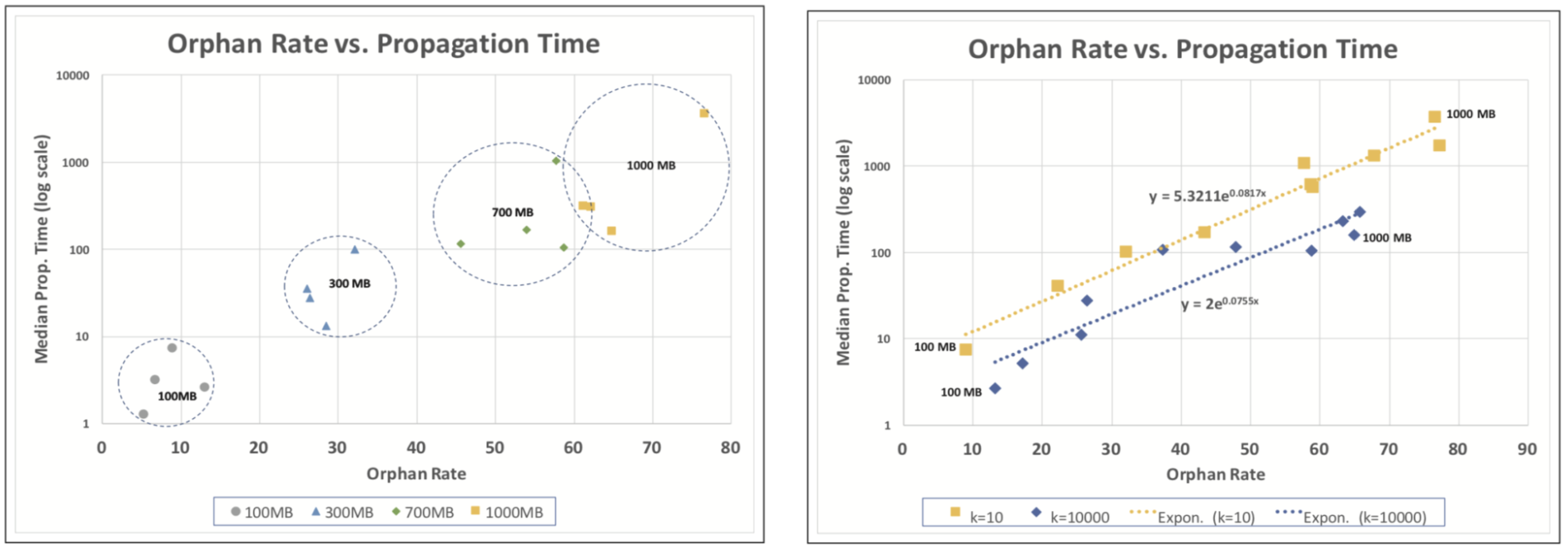
Relations between Orphaned Rate and Propagation Time as found in section 5 “Performance Evaluation” C4:
- As we see in the figures below, the median propagation time is exponentially proportional to the orphan rate; moreover, both the proportionality constant and the exponent is higher for k = 10 than k = 10000. Consequently, k = 10000 leads to overall lower orphan rates and median propagation times than k = 10.
- Note that the figure also shows that, as expected, both orphan rates and propagation times increase with the block size, where we plot the relationship between orphan rate and median propagation rate for different block sizes (100MB, 200MB, 700MB, and 1000MB) confirm this observation that both orphan rates and median propagation times increase with the block sizes (in the figures below, each dot corresponds to a different per-block symbol count, k)x.
Conclusion and Future Work:
Prior to “Velocity: Scalability Improvements in Block Propagation Through Rateless Erasure Coding”, it was believed that the Dash network could scale to a maximum of 4MB blocks using the ‘compact’ propagation approach, or to 10MB blocks using the ‘XThin’ approach while maintaining orphan rates below 1%. Results from “Velocity: Scalability Improvements in Block Propagation Through Rateless Erasure Coding” have shown that using the proposed Velocity protocol as part of hybrid propagation strategy can facilitate increases in block size which exceed previous estimates for a network which adopts this approach. It is to be noted that although orphan rates are higher than traditional methods, the levels of these rates are capped below a network consensus determined threshold. Current propagation techniques that result in fast propagation and low orphan rates for small blocks are highly dependent on memory pool synchronization. If memory pools (of the peers propagating blocks) do not synchronize, the methods fail to relay blocks faster and fall back on traditional propagation. Analyzing the above results, researching have concluded that utilizing data aggregation techniques on a node for data propagation works better than syncing blocks using one peer. The advantages when nodes relay symbols instead of the full blocks are detailed in section six of the research “Conclusions and Futurue Work”:
- Miners have the capability of multicasting. In our experiments, we have used simultaneously-scheduled uploads over TCP connections. These may serve large blocks to many nodes using continuous asynchronous streams, which is not possible in traditional relay approaches.
- The data received by a full node is downloaded through multiple peers in parallel, resulting in faster downloads.
The advantages listed above are to help nodes propagate larger blocks faster without increasing orphan rates by compromising amounts. It’s to be noted that Orphan rates do improve when sending fountain codes instead of fetching the block from a single client; an example is as followed: the rate for 100 MB blocks drops from 17% to 9%, increasing miner profitability while maintaining network consensus up to 600MB blocks, compared to 100MB for conventional approaches.
By significantly reducing the payload while sending a draft or sketch of the whole block, researchers have determined that orphan rates can be reduced while transmission speeds are increased. Looking towards the future, researchers from the ASU Blockchain Research Lab intend to explore the extension of these approaches through a hybrid method that leverages the advantages of fountain codes to improve the re-transmission of block data by methods of blocktxn, xblocktx and grblocktx, respectively. However, as mentioned at the beginning of this research synopsis, there’s always a caveat, and challenges still remain for the Velocity porpogation protocol and it’s team of researchers at Arizona State University.